Black Friday to termin, który przywędrował do nas zza Oceanu. W eCommerce oznacza czas wytężonej pracy dla sklepów online. Nie mniej pracy, i to dużo wcześniej, podejmuje zespół IT dostawcy platformy.
Chcemy pokazać w jakich pięciu głównych obszarach pracujemy nad wydajnością systemu, by w tak szczególnym dniu jak Black Friday osiągnąć dostępność sklepów na poziomie 100%, co za tym idzie - spełnić cele biznesowe klienta.
1. Dbanie o wydajne API zamiast indywidualnej optymalizacji sklepów
Często przed dużą akcją sprzedażową E-commerce managerowie zlecają firmom IT prace optymalizacyjne, które mają przyspieszyć działanie sklepu. Ma to zabezpieczać system przed niespodziewanym wyłączeniami, np. ze względu na przeciążenia baz danych, a w konsekwencji brakiem sprzedaży. Nasuwa się pytanie, dlaczego takie optymalizacje są w ogóle konieczne? Aby na nie odpowiedzieć, trzeba przyjrzeć się różnym sposobom pracy developerów w pewnych ekosystemach.
Część systemów jest tworzona w oparciu o architekturę monolityczną. To zespół zintegrowanych, współpracujących ze sobą komponentów i usług, które działają jak jeden program. To w systemach eCommerce ma swoje wady. Jednym z głównych problemów związanych z tą architekturą jest to, że wszystkie elementy sklepu muszą być ze sobą dobrze skoordynowane, aby system mógł działać jako całość. To oznacza, że jeden element może spowodować niedziałanie całej sprzedaży. Innym problemem jest to, że architektura monolityczna jest zwykle bardziej złożona i wymaga większych nakładów pracy, aby ją utrzymać i zapewnić jej sprawność.
W takiej architekturze podczas rozwoju niektórych systemów, webmasterzy (odpowiedzialni za warstwę front-end), często dodają inwidualnie zmiany bez konsultacji z zespołami back-end. Najczęściej wprowadzali je poza specjalnie przygotowanym do tego konkretnego celu API. Takimi zmianami mogły być np. bezpośrednie zapytania do bazy danych.
W przypadku tworzenia przykładowej pętli po bazie danych w szablonie HTML podczas normalnego okresu, takie rozwiązanie jest praktycznie niezauważalne. Jednak w przypadku zwiększonego ruchu, baza danych nagle otrzymuje wzmożoną ilość zapytań, co sprawia, że przestaje odpowiadać. Przez to serwis transakcyjny staje się niedostępny. Z tego powodu raz na jakiś czas zlecano optymalizację, która tak naprawdę najczęściej oznaczała przegląd zmian, przegląd szablonów, dodanie cache i sprawdzenie czy coś nie spowoduje niedostępności baz danych.
W 'merce to wygląda inaczej. Główną różnicą jest architektura MACH oraz sposób w jaki nasza autorska platforma eCommerce jest rozwijana. Z czterech części składowych architektury MACH (Microservice, API, Cloud, Headless) najistotniejsze są tu API i Headless eCommerce. Dzięki komunikacji danych poprzez API możemy bardzo precyzyjnie określić jakie dane chcemy i w jakiej formie otrzymać lub wysłać. Headless eCommerce natomiast oznacza niezależność warstwy front-end od warstwy back-end, uelastyczniające pracę nad rozwojem systemu oraz sprawiając, że niepożądane zachowania w jednej warstwie nie zastopują działania drugiej.
Więcej o architekturze MACH przeczytasz na naszym blogu: https://merce.com/blog/architektura-mach-rozwiazanie-gotowe-na-przyszlosc
Wydajność API badamy na podstawie metryk. Monitorujemy, które z endpointów są najczęściej używane, ile pochłaniają czasu, mocy procesorów, itp. Ta wiedza pozwala nam zlokalizować potencjalne problemy w przyszłości.
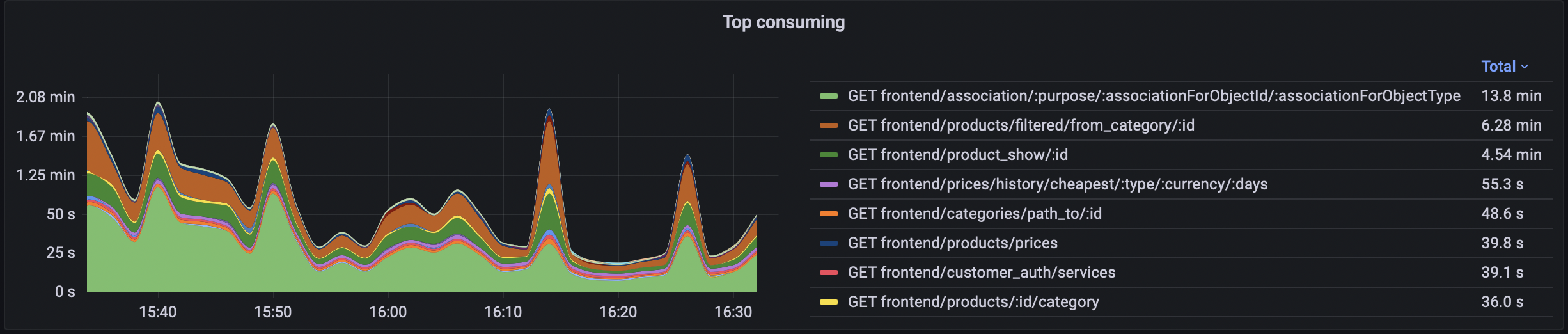
2. Stały monitoring i posiadanie planu na czarny scenariusz
Narzędzia takie jak Grafana są standardem w monitoringu metryk w IT. Jednak sama dobrze przygotowana infrastruktura i monitoring mogą czasami nie wystarczyć w przypadku kilkukrotnie większego niż standardowo ruchu. Chodzi o specyfikę systemów eCommerce.
Statyczne strony informacyjne, nawet bardzo duże, skaluje się w dość prosty sposób. Dlaczego? Każdy użytkownik dostaje w zasadzie taką samą treść. Jednolitość treści pozwala trzymać ją poza własnym serwerem, a w momencie przyjścia requestu od użytkownika, obsłużyć go z najbliższej geograficznie do zapytania serwerowni.
Największym wyzwaniem w eCommerce jest to, że praktycznie każdego użytkownika trzeba traktować indywidualnie. Każdy cennik, wybrana promocja, punkty lojalności, wykorzystana rekomendacja, finalna cena, stan magazynowy i sposób naliczania wszystkich wyżej wymienionych części składowych oraz fakt, że musi dziać się to na żywo, oznacza, że nie da się wyświetlać w tego samego wszystkim klientom czy cashować dane. To właśnie sprawia, że na przykład dwukrotnie większa liczba serwerów nie obsłuży dwukrotnie więcej użytkowników systemu eCommerce. Działa tu raczej wzrost wykładniczy niż liniowy. Dlatego wszystkie systemy przygotowujemy w oparciu o ideę MACH i monitorujemy narzędziami.
Jednak zawsze warto mieć scenariusz awaryjny. W momencie ogromnego obciążenia i w przypadku braku poprawy wydajności poprzez dodanie mocy obliczeniowej, podejmujemy inne działania. Wyłączamy wtedy endpointy, które potrafią znacząco odciążyć serwery, a które nie są krytyczne dla głównego celu systemu eCommerce, czyli transakcji. Przykładem takiego endpointa są na przykład asocjacje, czyli produkty rekomendowane.
3. Replikacja bazy danych MySQL wybranych procesów
Bazy danych, czyli instancje, serwery nie skalują się wertykalnie. Dodanie mocy obliczeniowej w postaci 20 procesorów do działających 20 nie sprawi, że będzie ona dwa razy szybsza i bardziej wydajna. Ten limit skalowalności nie da się więc rozwiązać prostym dokładaniem kolejnych zasobów. To ograniczenie można ominąć dodając kolejne serwery bazy danych i na nie przekierowywać wzmożony ruch. Jest to tak zwana skalowalność horyzontalna.
Jednak z dodawaniem kolejnych serwerów i ich replikacji wiąże się jeden problem - opóźnienie danych. I jeśli nawet jest to opóźnienie rzędu 100 milisekund, może dojść do sytuacji, w której użytkownik doda do koszyka produkty, ta informacja zostanie obsłużona przez standardową bazę i produkt wyświetli się w koszyku. Jednak jeśli w momencie dużego ruchu kolejne operacje będą obsługiwane przez replikę bazy danych, to po odświeżeniu w koszyku nie będzie żadnego produktu. Ta jedna operacja wpadła właśnie we wspomniane 100 milisekund.
Dlatego naszym rozwiązaniem jest replikacja całych bazy danych i używania replikacji do wydzielonych funkcjonalności, w których opóźnienie nie ma dużego znaczenia lub jest mniejsze niż cache. Takim miejscem są katalogi produktów. Odpowiadają za około 70% zasobów podczas standardowej transakcji. Ich składowe, jak na przykład nazwy produktów, zmieniają się dość rzadko, a w czasie akcji promocyjnych nie zmieniają się praktycznie w ogóle. Katalogi produktów ze względu na ilość danych pochłaniają dużo mocy obliczeniowej. Dlaczego tak się dzieje? Użytkownicy, zanim dodadzą produkty do koszyka, szukają ich, wykorzystują kategorie, filtry, itd. Żeby pokazać poprawne wyniki, system musi wykonać dużo operacji w tle: sprawdzić czy klient jest zalogowany, dobrać odpowiedni cennik, uwzględnić ewentualną promocję, itd.
Widząc to, dzielimy które endpointy kierować, w które miejsce. Jest to możliwe także ze względu na wykorzystanie rozwiązań headless eCommerce. W tym przypadku kilkusekundowe opóźnienie jest bezpieczne, nie mówią już o 100 milisekundach. Dzięki temu odciążymy główną bazę danych niezbędna do zapisu transakcji.
4. Stałe inwestycje sprzętowe w Data Center
Cloud to pojęcie technologicznie, ale zawsze na końcu są fizyczne serwery. Same podejście do architektury, wdrożenie headless eCommerce, narzędzi monitorujących, przygotowania planów B i C, nie powiedzie się bez infrastruktury fizycznej.
Dowiedz się dlaczego zdecydowaliśmy się stworzyć własne rozwiązanie cloud https://merce.com/blog/dlaczego-stworzylismy-wlasne-rozwiazanie-cloud
Systematycznie w ramach coraz większego ruchu generowanego przez systemy klientów, zwiększamy ilość zasobów fizycznych. Kupujemy kolejne serwery, konfigurujemy je, rozwijamy sieć, itd. Wszystko robimy z od kilku lat w Data Center należącym do Grupy 3S.

5. Zapewnienie bezpieczeństwa
Replikacja nie wpływa tylko na wzrost stabilności systemu eCommerce, ale także na jego bezpieczeństwo. Gdyby z jakiegoś powodu, główna baza danych zostałaby uszkodzona, w każdym momencie możemy ją zastąpić repliką, która jest generowana automatycznie w czasie rzeczywistym (opóźnienie rzędu pół sekundy) i z niej stworzyć bazę główną. Korzyścią jest też sprawa backupu wszystkich danych. Tworzenie kopii bezpieczeństwa bezpośrednio z głównej bazy może spowodować jej zablokowanie na kilkanaście sekund. Dlatego zawsze robimy backup z dedykowanej do tego repliki - jej chwilowe zablokowanie nie wpływa na jakąkolwiek aktywną bazę danych.
Wspomniane rozwiązania są dobrym standardem w platformach eCommerce. Jednak tworzenie replik, ich monitoring, zarządzanie backupami kilkuset bazami danych wszystkich klientów, to duże wyzwanie. Dlatego wprowadziliśmy szereg automatyzacji tych procesów, które ograniczają koszt utrzymania takiej ilości baz, oraz pozwalają zarządzać nim na podstawie metryk.
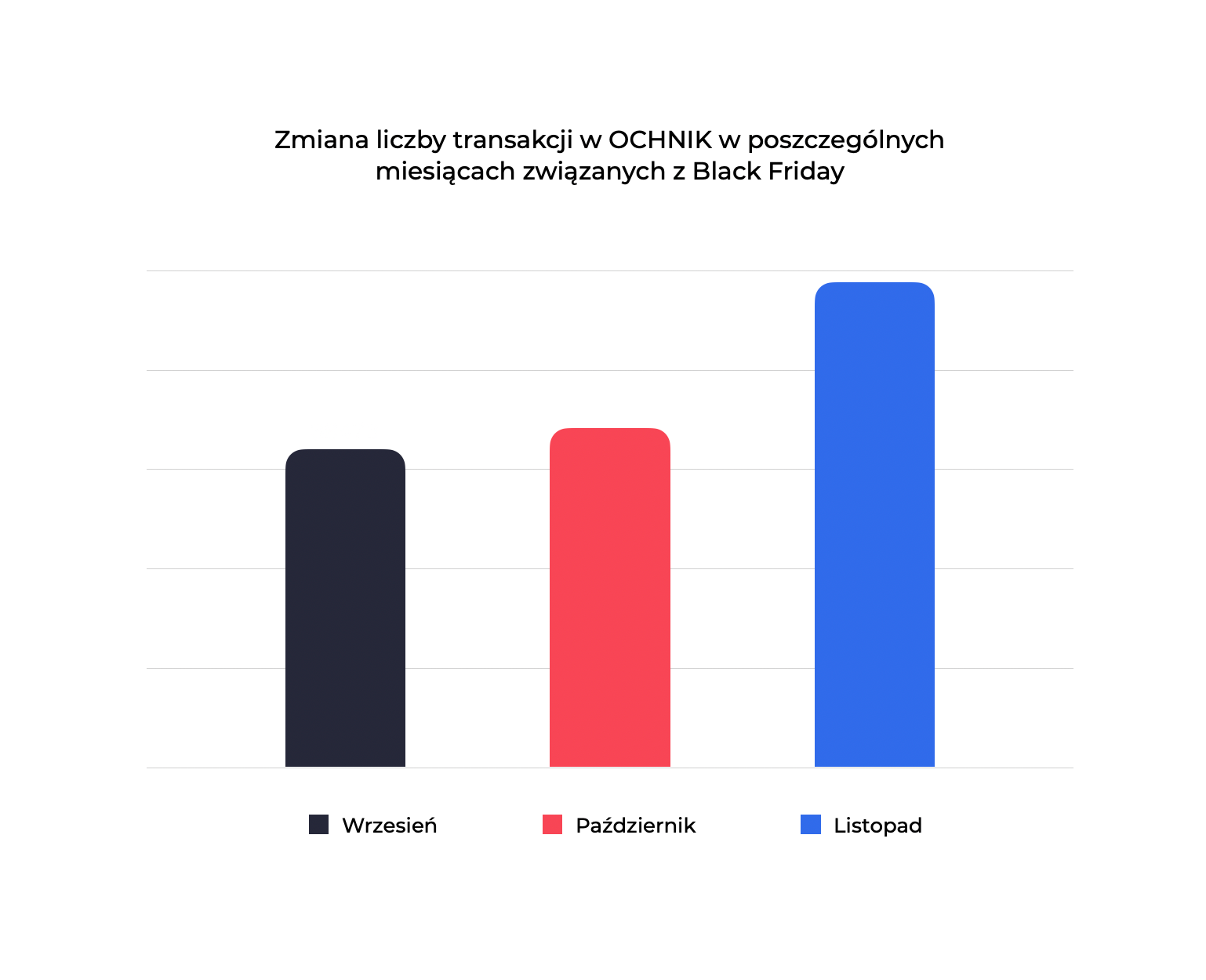
Dla marek detalicznych takie akcje jak Black Friday to ważna data w całorocznym kalendarzu sprzedaży. Dlatego zawsze już kilka tygodni wcześniej sygnalizujemy zespołowi merce, jaki poziom ruchu spodziewamy się wygenerować w naszym sklepie. Ostatni Black Friday był dla nas wyjątkowo intensywny, o czym świadczy wolumen sprzedaży i liczba transakcji. Cieszymy się, że za sprawą rozwiązań cloud merce sklep był dostępny dla naszych klientów przez cały czas.
Dawid Szrek, Manager ds. e-commerce i projektów IT w OCHNIK
Więcej o realizacji dla OCHNIK w case study: https://merce.com/realizacje/ochnik
Autorem tekstu jest Marcin Rutkowski.





