Gdy kilka lat temu zastanawialiśmy się, w jaki sposób szybko i stabilnie rozwijać platformę, metodologia CI/CD oraz systemy orkiestracji dopiero wchodziły na rynek. W tamtym czasie, będąc jeszcze Programistą PHP, nie spodziewałbym się, że w niedalekiej przyszłości zajmę się czymś, co dzisiaj nazywamy DevOps. Tym wpisem przedstawię jaką drogę przeszliśmy jako organizacja oraz jak zmieniała się moja rola w czasie wdrażania najlepszych standardów rozwoju oraz hostowania aplikacji, z wykorzystaniem praktyk CI/CD, systemu orkiestracji Kubernetes oraz rozwiązania Docker.
Sytuacja na początku podróży
Zanim opiszę szczegóły wdrażania poszczególnych rozwiązań, warto napisać z jakimi wyzwaniami borykaliśmy się jako organizacja. Można je opisać w dwóch punktach:
1. Fragmentacja
To doskonale znana na rynku sytuacja, którą można przedstawić na przykładzie systemu Android. W tym scenariuszu twórca oprogramowania buduje wersje release, która w następnym etapie musi zostać dostosowana przez producentów sprzętów do swoich wersji systemów wraz z nakładkami graficznymi, dodatkami funkcjonalnymi i innymi elementami. Przez to, docelowy odbiorca otrzymuje oprogramowanie ze sporym opóźnieniem, ponieważ nowa wersja systemu musi zostać „opakowana” wszystkimi customowymi funkcjami danego producenta i dokładnie przetestowana.
Nasze podejście było podobne – na głównej gałęzi repozytorium rozwijaliśmy bazową wersję platformy, która następnie musiała być domergowana do wersji klienta. To powodowało konflikty, setki testów manualnych i konieczność dodatkowej pracy nad stabilizacją. Dzięki nowemu podejściu, mogliśmy scentralizować rozwijany kod w jednym repozytorium przy użyciu metodologii Trunk Based Development i dostarczać wszędzie dokładnie ten sam obraz oprogramowania.
2. Różnice między środowiskami
Kolejnym wyzwaniem był fakt, że na każdym etapie rozwoju, oprogramowanie było uruchamiane w różnych środowiskach. Przykładowo, developer rozwijający wybraną funkcjonalność, uruchamiał system na lokalnym środowisku, które mogło różnić się od środowiska na kolejnych etapach pracy. Serwisy były konfigurowane niezależnie, a na różnicę środowisk mógł mieć wpływ nawet czas pomiędzy uruchomieniem poszczególnych projektów.
Odwzorowanie i uspójnienie lokalnych środowisk w skali klastra, pozwoliło nam na wspólne wersjonowanie infrastruktury na wszystkich etapach rozwoju oprogramowania. Mamy przez to możliwość łatwego dodawania nowych, przetestowanych serwisów, a następnie wdrożenie ich dla szeregu klientów. Świetnym przykładem takiego działania jest masowe wdrożenie replikacji MySQL, którą mogliśmy zrobić bez ręcznej pracy i zaangażowania wielu osób, a zamiast tego skupić się na aktualizacji serwisu MySQL i skonfigurowaniu replik. Dzięki takim rozwiązaniom, mamy ewolucyjny i przyrostowy rozwój infrastruktury wraz z jej konfiguracją.
Wyzwania środowiska lokalnego
Prace z produktem IT wymagają dużej wiedzy na temat infrastruktury. Aby rozwiązać to wyzwanie przenieśliśmy całą aplikację razem z infrastrukturą do kontenerów. Do lokalnej orkiestracji kontenerów użyliśmy systemu Docker, bowiem potrafił on mocno odwzorować środowisko produkcyjne w lokalnej skali i był lekki dla sprzętu. Dzięki temu, mogliśmy uruchomić aplikację wraz z infrastrukturą poleceniem z linii komend i nie musieliśmy rozwijać szczegółowej wiedzy na temat samej infrastruktury.

Nowe narzędzia mają jednak to do siebie, że rozwiązując jedne problemy, potrafią wygenerować nowe. Dla nas największym wyzwaniem była praca na lokalnych plikach w systemie OSX. Jako że niemal cała firma używa sprzętu Apple, a Docker natywnie działa na systemie Linux, wystąpił problem wolnego działania podmontowanych plików z komputera (hosta) do kontenerów Dockera.
Na pomoc w rozwiązaniu tego zagadnienia miał przyjść Unison. To dwukierunkowe narzędzie do synchronizacji plików pozwalające na automatyczne rozwiązywanie konfliktów. Dla mnie osobiście największą jego zaletą było to, iż całą logikę działania można było zamknąć w kontenerze, co nie wpływało w żaden sposób na pogorszenie sposobu uruchomienia infrastruktury. Z czasem jednak okazało się, że z powodu skali plików do obserwacji, zdarzało mu się gubić pliki oraz niepoprawnie rozwiązywać konflikty. Wymusiło to na nas ponowną analizę tego zagadnienia.
I tutaj pojawia się Mutagen, w tamtym czasie nowy gracz na rynku. Umożliwiał dedykowane rozwiązywanie synchronizacji plików pomiędzy hostem a kontenerem działając po API Dockera. To rozwiązanie dla mnie miało wadę - wymagało instalacji na hoście. Dlatego też, aby ukryć całą logikę naszej infrastruktury, postanowiliśmy stworzyć narzędzie do zarządzania całym środowiskiem deweloperskim.
Przeniesienie aplikacji do kontenerów pozwoliło nam na przeprowadzanie testów aplikacji na tak zwanych pipelinach, czyli ścieżkach automatycznych zadań w procesie CI/CD. Jednak szybko okazało się, że uruchamiane testy automatyczne były dużo bardziej restrykcyjne, niż testy przeprowadzane przez developera. Dodatkowo, ciężko było odtworzyć dany błąd na środowisku lokalnym, więc wymusiło to na nas dodanie możliwości uruchamiania całej infrastruktury testowej w skali lokalnej. Tę opcję dodaliśmy także do naszego narzędzia do zarządzania środowiskiem deweloperskim.
Spójność środowisk na każdym etapie rozwoju było bardzo ważne, gdyż umożliwiło na zminimalizowanie występowania błędów niezwiązanych z logiką biznesową lub kodem.
Po przeniesieniu do kontenerów uzyskaliśmy:
- całkowicie odseparowane środowisk,
- całkowicie odseparowane dane w volumenach,
- szybkie uruchomienie kolejnego środowiska, porównywalne z czasem dograniem brakujących obrazów czy stworzeniem klona repozytorium.
W drodze do CI/CD
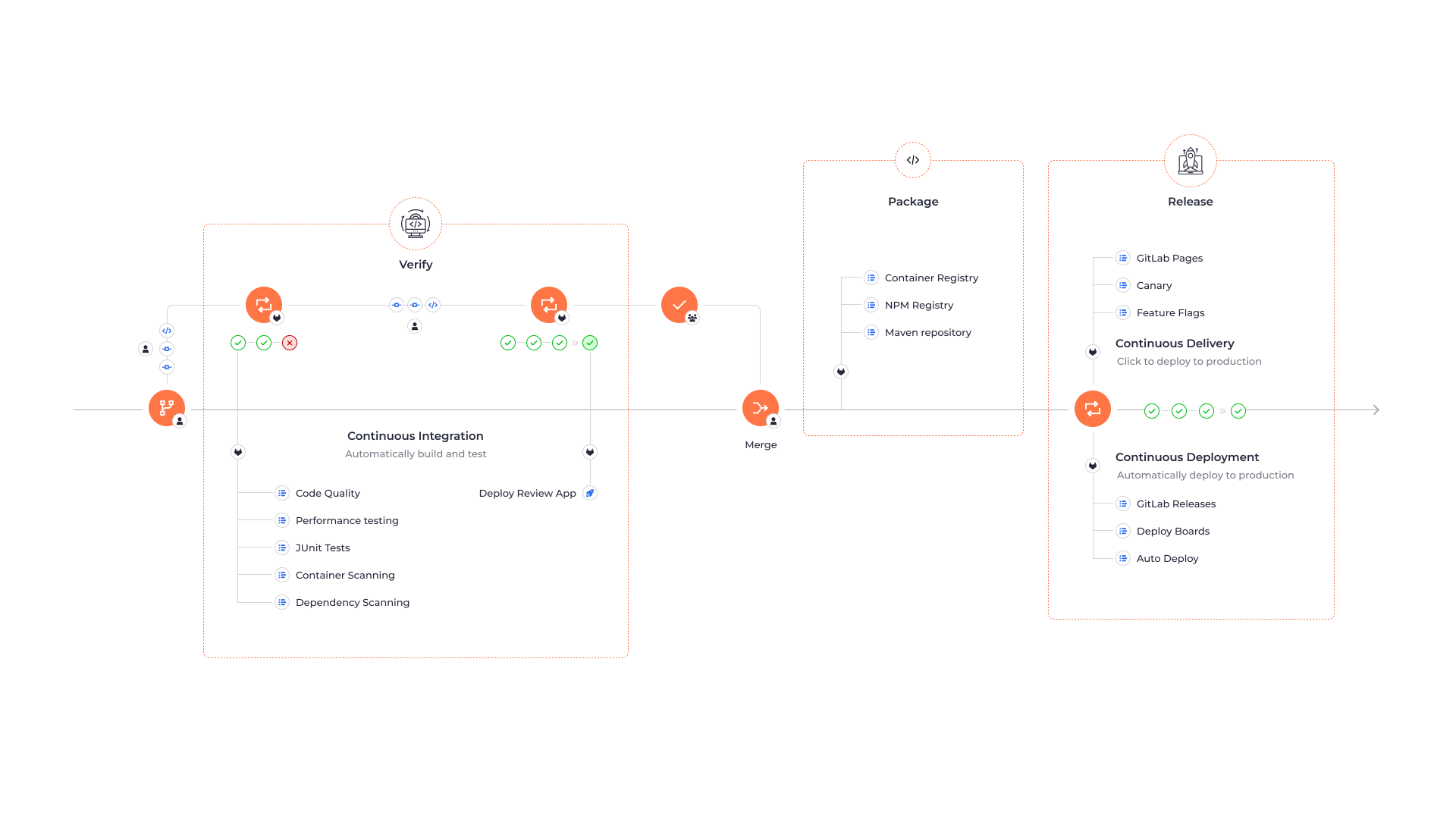
Zanim zaczęliśmy projektowanie pierwszych ścieżek CI/CD, musieliśmy wybrać narzędzia umożliwiające długotrwałe planowanie działań. Istnieje wiele narzędzi pozwalających na budowanie ścieżek CI. Od dłuższego czasu używając GitLab, postanowiliśmy dać szansę nowo wydanemu wtedy narzędziu GitLab CI. Wybór był strzałem w dziesiątkę, gdyż do dziś jest to prężnie rozwijane i używane na szeroką skalę narzędzie. W jaki sposób wybraliśmy Kubernetes jako narzędzie do orkiestracji obrazów na środowisku produkcyjnym? Było o nim wtedy głośno. Fakt, że za jego plecami stał gigant technologiczny - Google - dawał nam pewność, że możemy planować długofalowy rozwój na tej technologii, choć wszystkie narzędzia były wtedy w fazie alpha, z wyraźną adnotacją “Nie do użytku produkcyjnego”.
Planując uruchomienie pierwszych ścieżek CI/CD musieliśmy przygotować środowisko do uruchamiania zadań automatycznych. Pierwszym etapem było wdrożenie tak zwanego executora, czyli narzędzia orkiestrującego zadaniami automatycznymi na Dockerze w maszynie wirtualnej. Następnie przenieśliśmy się na klaster k8s (Kubernetes), aby maksymalnie odwzorować infrastrukturę aplikacji w skali klastra testowego. Sporym wyzwaniem takiego rozwiązania była potrzeba utrzymania ogromnej ilości środowisk testowych zawierających całą aplikację wraz z infrastrukturą. Dla samej corowej aplikacji jest to około 300 środowisk dziennie.
Od początku wdrażania obrazów Dockerowych wiedzieliśmy, że sami chcemy hostować obrazy. To wymagało wielu różnych rozwiązań. Problemem było utrzymanie dużej ich ilości, ponieważ rejestr Dockera nie posiadał żadnego sensownego rozwiązania na czyszczenie obrazów. To z kolei wymagało od nas testów kilku narzędzi. Podczas nich znaleźliśmy narzędzie Nexus od firmy Sonatype, które pozwala na definiowanie polityk czyszczenia obrazów. Musieliśmy więc definiować, który obraz jest używany w samym rejestrze. Postanowiliśmy więc pullować obrazy używane na klastrze - to zmienia ich datę ostatniej aktywności w rejestrze na obrazie. Te, które się nie zmieniają usuwamy po dwóch tygodniach.
W drodze do szybkiego CI/CD
Sporym wyzwaniem uruchamiania CI/CD jest optymalizacja szybkości. Dużym skokiem tego parametru okazało się usystematyzowanie budowania obrazów Dockerowych w zadaniach automatycznych. Polecanym rozwiązaniem jest ich budowanie w kontenerach to znaczy w dind, czyli w Docker in Docker. Jest to uruchamianie usługi w Dokerze w kontenerze na czysto. Wymaga to jednak każdorazowego ściągania wszystkich niezbędnych warstw od nowa, a że nasze CI buduje te same obrazy tylko z różnym kodem, ważne było, aby można było maksymalnie uprościć ten etap.
Dzisiaj można zastosować różne rozwiązania, np. łączyć się z serwerem Dockera poprzez połączenie remote czy montować sock z innego kontenera, który ma podmontowany storage. Dla nas najłatwiejszym rozwiązaniem było udostępnienie socka Dokcera z hosta. Pozwoliło to na użycie garbage collectora Kubernetesa, który sam dba o storage usuwając nieużywane warstwy obrazów. Ta niewielka zmiana pozwala zaoszczędzić nawet 80% czasu i zasobów. Montowanie socka Dockera hosta wydaje się być mało bezpiecznym rozwiązaniem, jednak nasz klaster pod zadania automatyczne jest typowo testowym środowiskiem i nie ma obaw z jego użyciem.
Optymalizacja
Na pewnym etapie, każdy zaczyna myśleć o optymalizacji kosztów środowisk testowych. Chcieliśmy to zrobić poprzez “wynajmowanie” maszyn potrzebnych na uruchamianie zadań testowych na publicznym cloudzie. Jednak po przeprowadzeniu Proof of Concept tego modelu, szybko okazało się że nasze klastry budowane latami są znacznie szybsze od publicznych rozwiązań.
Po przeniesieniu aplikacji do kontenerów, zaczęliśmy rozwój zgodnie z zasadami Trunk based development. To schemat ciągłej integracji, która wymaga maksymalnie częstego commitowania zmian do gałęzi głównej. Powodowało to chaos oraz częste blokowanie brancha, ze względu na to, że jeden pipeline potrafi trwać do godziny. W tym czasie mogło zostać zacommitowane nawet kilkanaście nowych zmian, także z błędami. Po takim czasie było to ciężkie do zdiagnozowania, a wycofanie zmian też nie zawsze było możliwe. Finalnie spowodowało to wstrzymanie całego procesu. Ze względu na to zmieniliśmy sposób ciągłej integracji poprzez maksymalnie częste mergowanie głównego brancha do gałęzi z rozwijanym kodem.
Dzięki temu, zmiany testujemy trójetapowo:
- pełny zestaw testów na etapie Merge Requesta. Po pozytywnym przejściu całego pipeline, możliwe jest dodanie zmian do głównej gałęzi,
- ponownie pełny zestaw testów, w celu uniknięcia problemu 2 way merge, czyli zmian wykluczających się na dwóch, różnych branchach wchodzących do głównej gałęzi jednocześnie. W ten sposób od razu z widzimy, że takie zmiany zostały wprowadzone i szybko możemy je wycofać lub naprawić,
- ścieżka testowa w momencie potrzeby opublikowania zmian na produkcji. W tym momencie testujemy wszystko wliczając w to konkretną aplikację frontową klienta.
Wykorzystywane technologie
Projektowania ścieżek CI/CD nie byłoby możliwe bez wspierających technologii. Na swojej drodze napotkaliśmy między innymi:
- Phpunit - najprostsze testy jednostkowe. Dzisiaj są standardowym, codziennie używanym rozwiązaniem. W naszym przypadku wyzwaniem było dopisanie ich do wielkiego monolitu, żeby nie mockować połowy systemu,
- kontrolery jakości kodu jak: Differ, Sniffer, PHPstan, które zapewniają poprawność kodu. W tym obszarze największym wyzwaniem było uruchomienie narzędzi w kodzie, który miał kilka lat,
- Behat jako pierwsze podejście do testów akceptacyjnych. Ówcześnie wybór wydawał się oczywisty, ponieważ Behat jest napisany w języku PHP, czyli tego samego z którego wywodzi się nasz produkt. Zakładaliśmy, że testy będą pisane przez deweloperów, jednak jak się szybko okazało, nie każdy deweloper chce być testerem. To oraz fakt, że Behat jako narzędzie rozwijało się dość wolno oraz słabo współpracował z aplikacjami frontendowymi, sprawiło, że rozpoczęliśmy rozglądać się za innymi narzędziami,
- Cypress - czyli nowoczesne rozwiązanie w javascript. Wymagało od nas przepisania wszystkich scenariuszy na tę technologię. Mimo to, spełniło nasze oczekiwania dotyczące testów. Więcej o tej zmianie przeczytasz na blogu: Dlaczego postawiliśmy na automatyzację testów E2E poprzez Cypress'a? https://merce.com/blog/dlaczego-postawilismy-na-automatyzacje-testow-e2e-poprzez-cypressa,
- Codeception - rozbudowane narzędzie do wszelkiego rodzajów testów. Używamy go najczęściej do testowania kontraktów REST API.
Stosowanie różnych podejść i różnych narzędzi finalnie zamieniło nam długie godziny testów manualnych z ponad 400 punktami na checkliście i godzinami stabilizacji na produkcji, na godzinny pipeline, który zawiera blisko 7 tysięcy testów jednostkowych, 400 testów e2e, 600 testów funkcjonalnych oraz prawie 1300 testów kontraktów.
Publikacja na środowisku produkcyjnym
Posiadając jedną aplikację ze stałą konfiguracją, publikację można robić za pomocą jednego pliku yaml. Jednak w systemach rozproszonych, potrzebny jest system templatowania. Gdy zaczynaliśmy używać systemu orkiestracji Kubernetesa, wszelkie narzędzia templatowania były dla nas niewystarczające, dlatego też napisaliśmy swoje w PHP. Wybraliśmy ten język, ponieważ wszyscy nasi początkujący DevOpsi wywodzili się z niego. Rozwiązanie to okazało się trudne w utrzymaniu i rozwoju. Z pomocą przyszedł nam Helm w wersji 3, który posiadał niemal wszystkie możliwości, jakich szukaliśmy. Mimo to, nie bazujemy w 100% na kubernetesowym “sterze”, jednak jest on naszą centralną częścią narzędzia, które rozszerza go o generowanie dynamicznych domen pod testy, generowania configów pod różne środowiska, a także tagowanie ich oraz wersjonowanie. Mając gotowy deployment, czyli manifest definiujący w pełni naszą aplikację wraz z infrastrukturą, musimy w jakiś sposób dostarczyć zmiany na klaster produkcyjny. W momencie w którym dopiero uczyliśmy się obsługi systemu orkiestracji, zmiany publikowane były ręcznie przez osoby mające pełny dostęp do klastra. Ostatecznie proces ten został zautomatyzowany.
Obecnie generujemy dostępy do określonych zasobów na określony czas i przechowujemy ich certyfikaty - wykorzystywane do komunikacji z klastrem - w bezpiecznym sejfie Vault od firmy HashiCorp. Na bazie certyfikatu podpisanego kluczem z klastra możemy zdefiniować role i uprawnienia. Dzięki tej samej metodzie, zadanie ścieżki CI/CD odpowiadające za deploy samo generuje sobie odpowiedni dostęp na czas potrzebny na wrzucenie zmian, dzięki czemu nie musimy się przejmować wyciekiem konfigu dostępowego.
Podejście CI/CD z pipelinami daje nam możliwość wersjonowania wersji Release Candidate do dwóch tygodni wstecz. W takim okresie utrzymujemy artefakty zadań automatycznych. Dodatkowo, każdą opublikowaną wersję przechowujemy w repozytorium, aby mieć wgląd na zmiany, co dodatkowo daje nam możliwość robienia rollbacków - choć to bardziej kwestia programistyczna niż infrastrukturalna, gdyż sama aplikacja musi umożliwiać takie możliwości.
Środowisko produkcyjne posiada wiele funkcjonalności i podsystemów, najciekawsze z nich, to:
- limitowanie serwisów - możemy to robić poprzez definiowania zasobów CPU oraz memory. Kolejno poprzez definicje w obiekcie parametru resources możemy ustawić requests oraz limit:
- requests - minimalna ilość zasobów, aby serwis mógł pojawić się na naszym nodzie, czyli maszynie w klastrze,
- limits - czyli jego maksymalne użycie cpu lub ramu. Procesor po osiągnięciu limitu zwyczajnie jest przycinany czyli throttluje, zaś ram łapie oom.
- overcommit zasobów - optymalizacji serwisów, aby mogły współdzielić zasoby. Jest to o tyle ważne, ponieważ rzadko wszystkie serwisy wykorzystują wszystkie przydzielone im zasoby. Wysokie limity są jedynie dla obsługi peaków, które bardzo sporadycznie nakładają się na siebie między serwisami,
- PriorityClass - jako automatyzacja lokalizacji serwisów pomiędzy maszynami klastra. Jest to obiekt który pozwala nam zdefiniować priorytet serwisów. Migruje on serwisy pomiędzy maszynami, aby zmieścić te ważniejsze czasami nawet kosztem tych z najniższym priorytetem. Bardzo ważne tutaj jest, aby pomyśleć o tym na samym początku wdrażania orkiestracji w systemie Kubernetes. Wdrożenie tego na działającym klastrze wymaga redystrybucji wszystkich podów na nowo - odczuliśmy to na własnej skórze mając już ponad 2000 podów które trzeba było zrestartować,
- HorizontalPodAutoscaling - czyli automatyczny system skalowania serwisów oparty o poziom utylizacji CPU. Pozwala zdefiniować minimalną i maksymalną ilość replik danego serwisu. Może być także oparty o customowe metryki, np. z Prometheusa. Idealnym przykładem wydaje się automatyczne skalowanie consumerów brokera AMQP w zależności od wielkości jego kolejki.
Od samych początków Kubernetesa problemem były dane. Bardzo popularnym sposobem montowania danych był protokół NFS. To interfejs sieciowy, dzięki któremu możemy podłączyć źródło do wielu replik jednocześnie. Jego zaletą jest prostota podłączenia, jednak narażony jest na utraty pakietów, co szczególnie jest bolesne przy stosowaniu do jakichkolwiek baz danych, powodujące częste awarie. To w sporadycznych sytuacjach wymagające nawet odtwarzania bazy z kopii zapasowej. Szukając rozwiązania tego problemu, jako jedno z najbardziej popularnych podejść było wyniesienie baz danych poza klaster Kubernetesa. Dla nas jednak nie była to opcja, ponieważ chcieliśmy mieć konfigurację projektu w jednym manifeście, które umożliwiłoby nam w prosty i szybki sposób przeniesienie całego środowiska na inny klaster Kubernetesa w razie potrzeby. Alternatywnie można było użyć metody `hostPath`, jednak to zabierało zalety orkiestracji, gdyż serwis taki był przyspawany do konkretnej maszyny (noda).
Dzisiaj zalecam wyniesienie wszystkich danych które się da poza klaster za pomocą, np. protokołu s3. Dodatkowo można użyć pluginu CSI (Container Storage Interface), który pojawił się w okolicach 2019 roku, umożliwiającym udostępnianie dostawcom przestrzeni dyskowej swoich produktów na prywatne cloudy k8s. Dzięki temu rozwiązaniu, możemy używać interfejsu ISCSI, który także jak NFS, działa po sieci ethernet. To jednak dysk blokowy, który dla systemu nie różni się niczym od dysku wpiętego w socket na płycie głównej. Dane przesyłane są blokowo, więc nie ma możliwości ich uszkodzenia. Protokół nie jest niczym nowym, jednak przed pojawieniem się tego pluginu użycie go wymagałoby ręcznego przepinania dysków pomiędzy maszynami, co ponownie pozbawiłoby nas wszystkich zalet automatycznej orkiestracji obrazów.
To tylko krótki wycinek historii z naszego podejścia do Kubernetesa i CI/CD. Jednak dzięki sporemu rozwojowi technologii i ogólnej dostępności wiedzy, nie trzeba się obawiać takiej transformacji.
Artykuł przygotował
Paweł Babilas DevOps w Merce.com





